“If we have data, let’s look at data. If all we have are opinions, let’s go with mine.” – Jim Barksdale, former Netscape CEO
Data are the facts or details from which information is derived
Throughout this course, know that we are combining data on the basis of location and individual attributes to form actionable information…
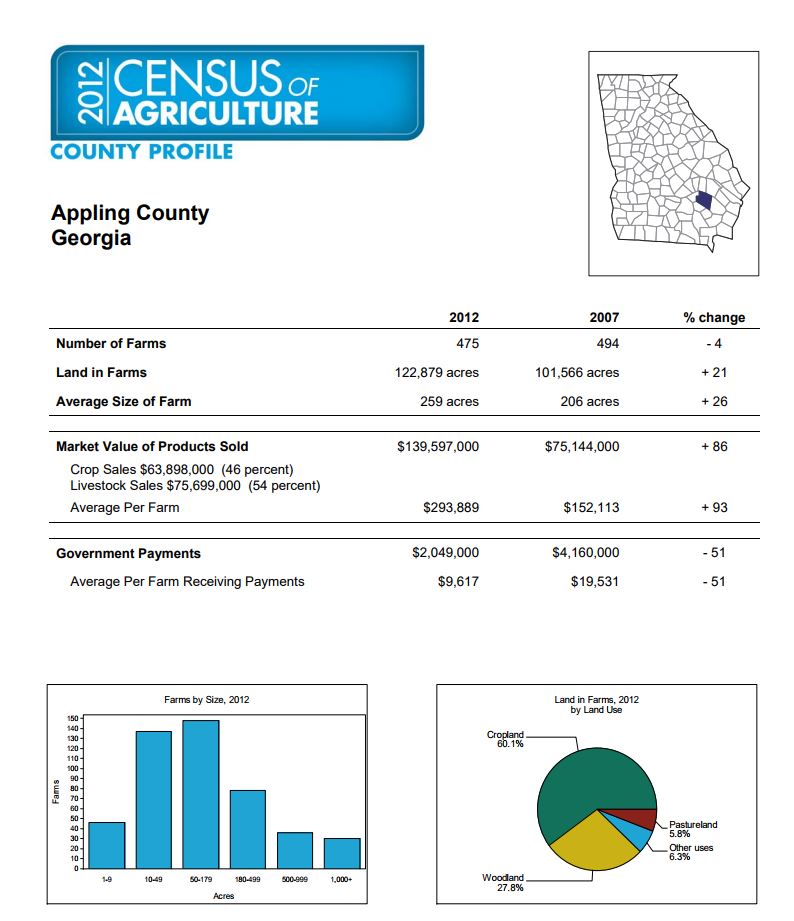
Data Compilation Example – 2012 Census of Agriculture
The Census of Agriculture is a complete count of U.S. farms and ranches and the people who operate them. Even small plots of land – whether rural or urban – growing fruit, vegetables or some food animals count if $1,000 or more of such products were raised and sold, or normally would have been sold, during the Census year.
The Census of Agriculture, taken only once every five years, looks at land use and ownership, operator characteristics, production practices, income and expenditures. For America’s farmers and ranchers, the Census of Agriculture is their voice, their future, and their opportunity.
Frequently asked questions about the 2017 Census.
Georgia 2012 Census County Profiles (external link)
Appling county profile (2012/2007):
Number of Farms: 475/494Land in Farms (acres): 122,879/101,566Average Size of Farm (acres): 259/206Market Value of Products Sold: $ 139,587,000/$75,144,000Average Per Farm: $293,889/$152,113
Government Payments: $2,049,000/$4,160,000Average Per Farm Receiving Payments: $9,617/$19,531
It is a trivial task to manually transcode the data for one county, but how long would it take to do this for the 159 counties in Georgia? What about for the 3,000+ counties in the US?
Extract data from a PDF with R
This approach only works because the PDFs use a structured and consistent format.
CensusAgStateIndex.csv (opens in Office 365)
CensusAgStateNames.csv (opens in Office 365)
##########load the tool to process the PDFs
library(pdftools)
library(httr)
##########set the working directory
##########YOU NEED TO CHANGE THIS TO MATCH YOUR WORKING DIRECTORY!!!!!!!!!
setwd("U:/Fall2017/FORS7690/AgCensus2012/PDFDownload/")
##########I store the information in the CensusAgStateIndex.csv file as idxfile
idxfile<- read.csv("CensusAgStateIndex.csv",stringsAsFactors=FALSE,sep=",",colClasses=c("FIPS"="character","StateFIPS"="character"))
##########theDatList is an R list in which I store the bits of data I am interested in
theDatList<- list()
##########baseURL is the non-changing part of the PDF URLs
baseURL<- "https://www.agcensus.usda.gov/Publications/2012/Online_Resources/County_Profiles/"
##########I create a text file called AgCensusOut and write the first line, the hedders
write("FIPS,CountyName,StateName,NumberOfFarms12,NumberOfFarms07,NumberOfFarmsPChange,LandInFarms12,LandInFarms07,LandInFarmsPctChange,AvSizeFarm12,AvSizeFarm07,AvSizeFarmPctChange,MktValue12,MktValue07,MktValuePctChange,CropSales,LiveStockSales,AvMktVal12,AvMktVal07,AvMktValPctChange,GovPmts12,GovPmts07,GovPmtsPctChange,AvGovPmts12,AvGovPmts07,AvGovPmtsPctChange",file="AgCensusOut_edit2.txt")
##########Beginning of the for loop, loops through each entry in idxfile
########For testing purposes, I have limited download to the first 10 records
####for (i in 1:3142){
for (i in 1:10){
##########read information from idxfile and concatenate
endURL<-paste(idxfile[i,5],"/cp",idxfile[i,3],".pdf",sep="")
##########concatenate the baseURL and the endURL
theURL<- paste(baseURL,endURL,sep="")
theOutPDF<- paste(idxfile[i,3],".pdf",sep="")
##########The following is an error check. The next line tests if 'theURL' points to a valid file. If it is not a valid URL, the value of the 'response' variable is 404. The response status is tested in the IF/ELSE statement that follows. If the URL is NOT valid, then the URL is printed to the screen (and the next URL in the list is processed). If the URL is valid, then the PDF is downloaded and processed
response <- httr::GET(theURL)
if(response$status_code > 400){
outtextlist<- paste(idxfile[i,3],idxfile[i,1],idxfile[i,5],", , , , , , , , , , , , , , , , , , , , , , ," ,sep=",")
write(outtextlist,file="AgCensusOut_edit2.txt",sep=",",append=TRUE)
} else {
download.file(theURL,theOutPDF,mode="wb")
##########convert the PDF to text
thefilename<- theOutPDF
txt<- pdf_text(thefilename)
print (thefilename)
#####Use Regex to remove the word acres and remove the $ sign and to remove commas and to remove the word "County"
txt<- gsub("acres","",txt)
txt<- gsub("\\$","",txt)
txt<- gsub(",","",txt)
txt<- gsub(" County","",txt)
#####Use Regex to remove the spaces after the + and - signs
txt<<- gsub("\\+ ","+",txt)
txt<- gsub("\\- ","-",txt)
#####Split the txt string by carriage and new line returns - "\r\n"
txtdat<- strsplit(txt,'\r\n')
#####Parse individual lines of the txtdat list. This works because of the structured nature of the Ag Census PDFs
CountyName<- txtdat[[1]][1]
StateName<- txtdat[[1]][2]
NumberOfFarms12<- strsplit(txtdat[[1]][4],'\\s{2,}')[[1]][3]
NumberOfFarms07<- strsplit(txtdat[[1]][4],'\\s{2,}')[[1]][4]
NumberOfFarmsPChange<- strsplit(txtdat[[1]][4],'\\s{2,}')[[1]][5]
LandInFarms12<- strsplit(txtdat[[1]][5],'\\s{2,}')[[1]][3]
LandInFarms07<- strsplit(txtdat[[1]][5],'\\s{2,}')[[1]][4]
LandInFarmsPctChange<- strsplit(txtdat[[1]][5],'\\s{2,}')[[1]][5]
AvSizeFarm12<- strsplit(txtdat[[1]][6],'\\s{2,}')[[1]][3]
AvSizeFarm07<- strsplit(txtdat[[1]][6],'\\s{2,}')[[1]][4]
AvSizeFarmPctChange<- strsplit(txtdat[[1]][6],'\\s{2,}')[[1]][5]
MktValue12<- strsplit(txtdat[[1]][7],'\\s{2,}')[[1]][3]
MktValue07<- strsplit(txtdat[[1]][7],'\\s{2,}')[[1]][4]
MktValuePctChange<- strsplit(txtdat[[1]][7],'\\s{2,}')[[1]][5]
#####Crop and livestock sales here
CropSales<- strsplit(txtdat[[1]][8],'\\s{1,}')[[1]][4]
LiveStockSales<- strsplit(txtdat[[1]][9],'\\s{1,}')[[1]][4]
AvMktVal12<- strsplit(txtdat[[1]][10],'\\s{2,}')[[1]][3]
AvMktVal07<- strsplit(txtdat[[1]][10],'\\s{2,}')[[1]][4]
AvMktValPctChange<- strsplit(txtdat[[1]][10],'\\s{2,}')[[1]][5]
GovPmts12<- strsplit(txtdat[[1]][11],'\\s{2,}')[[1]][3]
GovPmts07<- strsplit(txtdat[[1]][11],'\\s{2,}')[[1]][4]
GovPmtsPctChange<- strsplit(txtdat[[1]][11],'\\s{2,}')[[1]][5]
AvGovPmts12<- strsplit(txtdat[[1]][12],'\\s{2,}')[[1]][3]
AvGovPmts07<- strsplit(txtdat[[1]][12],'\\s{2,}')[[1]][4]
AvGovPmtsPctChange<- strsplit(txtdat[[1]][12],'\\s{2,}')[[1]][5]
#####Flatten the information (1 row, many fields)
if (is.na(NumberOfFarms12) | is.na(NumberOfFarms07)) {
outtextlist<- paste(idxfile[i,3],idxfile[i,1],idxfile[i,5],", , , , , , , , , , , , , , , , , , , , , , ," ,sep=",")
} else {
outtextlist<- paste(idxfile[i,3],CountyName,StateName,NumberOfFarms12,NumberOfFarms07,NumberOfFarmsPChange,LandInFarms12,LandInFarms07,LandInFarmsPctChange,AvSizeFarm12,AvSizeFarm07,AvSizeFarmPctChange,MktValue12,MktValue07,MktValuePctChange,CropSales,LiveStockSales,AvMktVal12,AvMktVal07,AvMktValPctChange,GovPmts12,GovPmts07,GovPmtsPctChange,AvGovPmts12,AvGovPmts07,AvGovPmtsPctChange,sep=",")
}
##########append to AgCensusOut.txt
write(outtextlist,file="AgCensusOut_edit2.txt",sep=",",append=TRUE)
}
}
Here is a description of the R code above:
(lines 2 and 3) We are using the pdftools and the httr R packages. If you are using RStudio, goto Tools > Install Packages… to install them(line 6) I set the working directory with the setwd command. Change this path to match a valid directory on your computer – notice the forward slash(line 8) I set up a CSV that contains the US county names, county FIPS, state name, state abbreviation, and state FIPS (Federal Information Processing Standard). This information, along with the baseURL from line 12, is used to create URLs which point to the existing 2012 Agriculture Census PDF county summaries. The entries are stored in an R list called ‘idxfile’.(line 14) Create a new text file called ‘AgCensusOut.txt’ to store the information we scrape from the PDFs and insert the data headers (the field names)(line 18) For testing purposes, I limit this loop to 10 iterations. To run for all counties, comment line 18 and uncomment line 17. Each entry in the idxfile list is processed separately.(lines 20, 22, and 23) Bits of the Agriculture Census PDF file names are read from idxfile and concatenated to form the structured PDF URL.(line 25) A handful of counties do not have reports. These missing reports cause the R script to fail when the download.file call in line 30 is made. I use the httr library to first check if theOutPDF variable points to a valid file. If this file is missing on the agcensus.usda.gov server, then the httr::GET command returns a value of 404 and that value is assigned to the variable I call response. If the theOutPDF points to a file that does exist, then response variable is assigned a value of 200.(line 26) If theOutPDF is NOT a valid file (response = 404), write the county FIPS, county name, and state name, and a bunch of blanks to the output text file and then move to the next line in the idxfile list (go back to line18 and repeat the process for the next entry in the idxfile). Otherwise, process lines 30 – 88.(line 30) Download the PDF to your working directory(line 33) Convert the PDF to text using the pdftools package(lines 36 – 44) I am using the R gsub command and regular expressions (REGEX) to search for various strings of text I found that cause errors when processing the final dataset. (Line 36) removes the word ‘acres’, line 37 removes all dollar signs, …, (line 44) removes carriage returns and new line marks.(line 44) the variable txtdat contains the formatted and edited text from both pages of the PDF. Within RStudio, type txtdat[[1]] in the interpreter to see the data stored in this variable from the first page and txtdat[[2]] to see the information from the second page. txtdat is a list with multiple records, so to access the first entry on the first page, type txtdat[[1]][1] — this will display the county name. If you type txtdat[[1]][2], then you will see the state name. txtdat[[1]][12] returns the average government payment text.(lines 47 – 79) I parse the txtdat variable and store the bits of information I want to save out as a new variable.(lines 82 – 85) Some of the variables have a value of NA. The command is.na(variable) returns TRUE if that variable is in fact NA and FALSE is the variable associated with the number of farms from 12 or from 07 variable contains valid information. If TRUE, store the county FIPS, county name, state name, and a bunch of blanks to the variable outtextlist. If FALSE (if the number of farms in 12 and 07 do contain numbers), then store this information to outtextlist.(line 88) write outtextlist to the AgCensusOut_edit2.txt file using a comma to separate the bits of information and appending this information to the end of the file.
I wrote this script in a trial-and-error manner. I figured out how to read a CSV, then assign bits of each record to a variable, how to combine them to form a valid URL string, and so on… If you know how to do these things already, great. If you don’t (or forgot how), try something like this or this – chances are that somebody has already written a how-to for you. Lines 36 – 44 required me to run the script for 100s of files and look at the output to determine if anything went wrong. I found several instances of non-structured formatting like a space after the minus sign and commas in numbers which caused the interpreter to consider the number as a string. Each time I found one of these issues, I added a line to the code.
Before attempting to use this dataset in an analysis, you should open it in a text editor and LOOK at the data. USE NOTEPAD++ (link) – do not use Word. Scroll through the document and look for abnormalities.
I still see some instances of (D) and NA. Do a Find-and-Replace and change (D) to – and NA to –.Save the csv file
The format of the FIPS code column is important. It must be a 5-character string so we can join this external tabular dataset to the county boundaries later on. Some softwares like Excel and Access will automatically format this field as numeric and the leading 0 will be lost. If you want to view the data, use something like NOTEPAD++ and avoid opening this file in Excel, Access, and even Word if you plan to use in the GIS.
US_Counties_Shapefile (zipped)
Next step, data visualization & data summary…
.